This is combined with the incredible general feeling that automatic programming can be evaluated as producing the same results regardless of the user using it. Something true only with benchmarks, basically. Benchmarks are useful metrics because even if weak we need some guidance, but the current real world dynamic is that AI will completely change what it is capable of doing based on the programmer using it.
Maybe never in the history of programming there was a time where diverse programming skills were as important as today (but this may change as AI evolves).
That's something I've argued here several time and that's actually rarely done. Namely it's totally different when a non-developer use such tool for programming vs when a (senior) SWE does. That's a fundamental point which IMHO a potential for (non-riskfree) augmentation versus replacement. Replacement though makes for excellent narrative (if not scapegoat) yet if the tool is "productive" (with KPIs to agree on) only with skilled staff that it's not the reality, just a "wish".
they are definitely useful but they miss the things that are hard to encode in tests, like spec/intent alignment, scope creep, adherence to codebase patterns, team preferences (risk tolerance, etc)
and those factors are really important. which means that test-evals should be relied upon more as weak/directional priors than as definitive measures of real-world usefulness
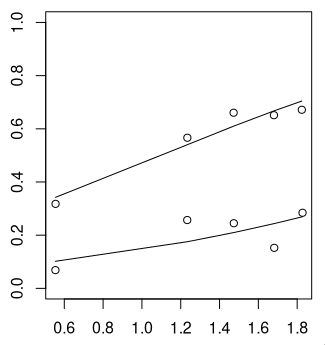
Interestingly, I had a similar finding where, on the 3 open-source repos I ran evals on, the models (5.1-codex-mini, 5.3-codex, 5.4) all had relatively similar test scores, but when looking at other metrics, such as code quality, or equivalence to the original PR the task was based on, they had massive differences. posted results here if anyone is curious https://www.stet.sh/leaderboard
I’ve been building out internal linters that enforce design patterns I want and raise common code smells (also note tools like eslint allow custom rules which are easy write with something like opus 4.6). The use case is a total refactor of react and fastapi apps. We are suffering from everything’s a snowflake syndrome and just want the same pattern employed across features.
This works pretty well when the linter has a companion agents.md file which explains the architecture and way about the world.
But to get the agent (Claude code opus 4.6 currently) to nail the directory structure and design primitives, and limit some doofus behavior, I still haven’t cracked how to make literally each line of code simple and sensible. And I haven’t figured out how to prevent agents from going out of bounds and doing weird things unless I catch it in review and add another rule.
This is a relatively new endeavor, but my gut is that it’s not much more time (linter rules and perhaps “evals” or a beefy agent review cycle) before I have bespoke linters in place that force what I want from our architecture.
Note that a huge bottleneck to all of this is that the codebase our current team inherited has no tests. It’s too easy to accidentally nuke a screen’s subtle details. It’s also really hard to write good tests without knowing what all of the functionality is. It feels like a blocker to a lot of large-swath agentic changes is a test strategy or solution first then a rigid push for rearchitecture or new design.
having linters is super important IMO - I never try to make the AI do a linter's job. let the AI focus on the hard stuff - architecture, maintainability, cleanliness, and the linter can handle the boring pieces.
I also definitely see the AI making changes that are way larger than necessary. I try to capture that in the eval by comparing a "footprint risk" which is essentially how many unnecessary changes did the AI make vs the original PR.
I would certainly like to move beyond using PRs as a sole source of truth, since humans don't always write great code either. Maybe having LLM-as-a-judge looking for scope creep/bloat would be a decent band-aid?
In my job in internal controls at a multinational company, I see this pattern. Teams choose an LLM for compliance tasks because it scored well on a general-purpose benchmark. Later, they find out it confidently creates regulatory citations that seem perfectly credible. The tests it "passes" have nothing to do with the important judgment calls.
Bisonbear's method of creating repo-specific evaluations is spot on. The only evaluation that truly matters is the one you conduct with your own data, using your own quality criteria. The real question is whether we can make that affordable enough so every team actually does it instead of relying on the leaderboard.
This transformation will rule out confidence ranges with negative time.
BTW, log-normal distribution tend to produces events P(x>E(X)+d) more frequently than events P(x<E(X)-d). If one needs reasons why software projects often late, this is one of them.
Is this a post about AI archeology?
For the most part, I think the tests AI have been given have been appropriately designed. At release, many AIs do poorly at them, the models rapidly catch up until the point where a new test is needed.
They should be measuring close to the limits of ability like that.
There will be some that try and steal headlines by targeting the specific nature of the test, but that is not a long term winning solution, the tests keep getting harder. If they make a model good at every test it has seen without regression, then with enough tests, that too ceases to be a problem.
Perhaps there should be an aggregate AI test score that evaluates all of the tests released in a given year. If a model passes the latest test really well but does worse at TestSet2024 than the models before, it would perhaps indicate the model being trained to pass the latest cool test.
There is a problem with people interpreting an AI that passes a test of X,Y or Z as indicating that the AI has the abilities of a human who passes X,Y, or Z. You should tell people who say that, Kasparov makes a nice coffee.
You can also measure the crossentropy, which is essentially the whole program entropy above minus entropy of the programming language and functions from standard libraries (i.e. abstractions that you assume are generally known). This is useful to evaluate the conformance to "standard" abstractions.
There is also a way to measure a "maximum entropy" using types, by counting number of states a data type can represent. The maximum entropy of a function is a crossentropy between inputs and outputs (treating the function like a communication channel).
The "difference" (I am not sure how to make them convertible) between "maximum entropy" and "function entropy" (size in bits) then shows how good your understanding (compared to specification expressed in type signature) of the function is.
I have been advocating for some time that we use entropy measures (and information theory) in SW engineering to do estimation of complexity (and thus time required for a change).
The simplest reasonable model would be logistic regression. It's also got 2 parameters and the range is correct.
{kind=link}
As agent-generated PRs scale, "all tests green" becomes necessary but nowhere near sufficient. The merge gate is becoming the real bottleneck, and it needs different evaluation criteria than CI.
Take a second look at the "reasons for rejection". A quarter or so of the changes that pass tests actually don't solve the problem they intend to. The tests used in SWE-bench do not discriminate all that well between working and broken solutions.
I've been thinking about tools for organizing long AI conversations.
Scrolling through hundreds of messages quickly becomes painful. I'm curious how people here manage long AI chats.
[1] https://big-stupid-jellyfish.github.io/GFMath/pages/llm-quan...
These statements are silly, because the only interesting comparison is among models with highly comparable on-disk sizes, or sizes for their active parameters. Obviously, a Q4 model is not going to be the same effectiveness as a Q6: no one sensibly expects that, you need to compare the Q4 with a smaller model. (The GP has the same problem of course.) I believe that once you do that kind of comparison, higher quantizations tend to do better up to Q2 or so for casual chat, maybe slightly more bits-per-param for agentic use cases where avoiding erratic behavior is important.
I've been thinking a lot about tools for organizing long AI conversations. Curious how people here currently manage them.
Also, some people would have spoken outright rejecting any AI code, but most maintainers would employ the silent treatment tactics. And then when you demand them to review, they either close it or say that "I'm too busy" as an argument. I would call this one of the biggest dick move, because it hurts the most yet you can't find anything wrong with them until they reveal their motives.
I don’t think that’s a fair characterization. You don’t know if the maintainer/reviewer is overloaded. No one is obligated to accept/review PRs and there is no question that the amount of noise has gone up. You are not the main character in that story, so to speak.
If you can't write a description in your own words explaining why you're doing it, why should they take the time reviewing it (which they did on the same day you posted it, btw, even if one of them wasn't pleased)? It makes it seem much less likely that you read the code yourself.
You might want to think carefully about why you chose to use the word "demand" there.
(Personally, if I'm rejecting AI slop, I'm not going to do it silently. But there are any number of valid reasons to not jump on someone's PR to review it.)
But hey, the tests pass!
If I force it to use plan mode for everything and babysit it, it can work really well, but it's really just acting as a faster typer for me, which is great. But it requires an experienced dev steering it.
but is it better than than the way a human would choose? And does it matter?
A compiler may write assembly in a way that no humans would choose either. And in the early days of compilers, where most programmers would still hand-weave assembly, they would scoff at these generated assemblies as being bad.
Not to mention that in games like go, the "AI" choosing moves that no humans would choose meant it surpassed humans!
In other words, solving a problem "in a way humans would choose to" is distinct from just solving a problem, and imho, not always required at all.
Humans write code in a lot of different ways.
Edit: I see another green comment was flagged for AI, might be indicative of something, but why so many green comments on this thread specifically?
* Triplets
* X isn't Y, it's Z
* X but Y
* Wording that looks good at first pass, but when you read closely actually makes no sense in the context of the discussion: "fixing the symptom instead of the root cause"
Flagged.
What's wrong with that?
~The comment you're replying to doesn't have any sentence of the form "X isn't Y, it's Z". It has "It's not X - it's Y".~ I see it now - it does have one "X isn't Y, it's Z" but that's hardly conclusive IMO.
While the comment does have "X but Y", it has a consistent mistake in punctuation - "X, but Y" would be the correct form, won't it? If an LLM produced this, I wouldn't expect the missing punctuation.
How does "fixing the symptom instead of the root cause" not make sense in the context of this discussion which is about coding agents producing marginal PRs.
I am literally right now tuning my PR, Claude instructions, and PR instructions to match our standards.
Funny enough I'm having the opposite problem where Claude is lowering its rating of my PR because my testing, documentation, and error handling is better than the other code in the repository so it doesn't match and therefore gets a worse grade.
I don't need it to try any harder without explicit instructions.
In any case, the blinding didn't stop Reviewer #2 from calling out obvious AI slop. (Figure 5)
If you look at the comment it says what the code following the comment does. It doesn't matter whether it is a human or a machine that wrote it. It is useless. It is actually worse than useless because if someone needs to change the code, now they need to change two things. So in that sense, you just made twice the work for anyone who touches the code after you and for what benefit?
That "appears" is doing a lot of heavy lifting.
The code working isn't what's being selected for.
The code looking convincing IS what is being selected for.
That distinction is massive.
The analogy is a new hire with full access to the wiki and Slack history vs. someone who's been on the team six months. The new hire can look things up; the veteran has already synthesized it into judgment that fires before they write a line. Agents currently operate like very fast new hires — great at retrieval, weak on the accumulated synthesis.
So you don't have to retrieve the whole history all the time.
It's similar to telling your new hire to catch up on _all_ the slack history. Only that the agent will actually do so.
Please read the guidelines before posting here: https://news.ycombinator.com/newsguidelines.html#generated
2. Repeated short phrases ("Tests still passed. Build still passed."). This is the new "it's not x, it's y" for me.
3. Ends on a sentence that pointlessly summarises the comment.
4. One-day old account.
5. Bio says "Building AI"
6. Criticises AI despite the bio.
7. Pangram says the comment is 100% AI.
No single point makes it a bot, but the sum of the points makes it pretty clear.
If they're not already, I wonder if LLMs will get better at disguising this (avoiding the tells, inserting mistakes etc.)
I also wonder if there comes a point where we as a culture imitate this style.
Together with its inherent training becoming an average of the world. In a world where average isn’t good enough.
Or rather. Good code quality is an uphill battle you need to fight for every time you look around in the code base, to prevent the world leaking in, and the better the quality gets the more good code will the agent have in its context when it generates new code.
Code works fine, but why use lots of code when little of code will do?
For me the big takeaway is that passing doesn't automatically mean it is maintainable, follows established patterns / conventions or have unexpected side effects that real reviewers care about.
It generated an implementation that worked well, but I hated the ~480 lines of code. The structure and flow was just... weird. It was hard to follow and I was seriously bugged by it.
So I asked it to reimplement it with some simplifications I gave it. It dutifully executed, producing a result >600 lines long. The flow was simpler and easier to follow, but still seemed excessive for the task at hand.
So I rolled up my sleeves and started deleting code and making changes manually. A little bit later, I had it down to <230 lines with a flow that was extremely easy to read and understand.
So yeah, I can totally see many SWE-bench-passing PRs being functionally correct but still terrible code that I would not accept.
And the colleages tend to do reviews with the help of the agents so they don't even care to read this mess.
Do you have any examples or resources that worked well for you?
Writing prompts and writing code takes about the same amount of time, for the same amount of text, plus there's the extra time that the LLM takes to accomplish the task, and review time afterwards. So you might as well just write the code yourself if you have to specify every tiny implementation detail in the prompt.
A guy with a mug comes up to a person standing with their laptop on a small table. The mug guy says, "Some day we won't even need coders any more. We'll be able to just write the specification and the program will write itself."
Guy with laptop looks up. "Oh, wow, you're right! We'll be able to write a comprehensive and precise spec and bam, we won't need programmers any more!"
Guy with mug takes a sip. "Exactly!"
Guy with laptop says, "And do you know the industry term for a project specification that is comprehensive and precise enough to generate a program?"
"Uh... no..."
"Code. It's called code."
Of course there are some systems where correctness is vital, and for those I'd like a precise spec and proof of correctness. But I think there's a huge bulk of code where formal specification impedes what should be a process of learning and adapting.
The UX is there, for small things it does work for me, but there is still something left for LLMs to truly capture major issues.
I'm still struggling to move past the magic trick of guessing what characters come next to ascribe understanding of "how" and implying understanding?
Using this particular example, if you simply paste the exact code into the prompt, the model should able to reproduce it. Now, you can start removing the bits and see how much you can remove from the prompt, e.g. simplify it to pseudocode, etc. Then you can push it further and try to switch from the pseudocode to the architecture, etc.
That way, you'll start from something that's working and work backwards rather than trying to get there in the absence of a clear path.
It is important to start a new chat so the model is not stuck in its previous mindset, and it is beneficial to have tests to verify that the simplified code still works as it did before.
Telling the model to generate concise code did not work for me, because LLMs do not know beforehand what they are going to write, so they are rarely able to refactor existing code to break out common functionality into reusable functions. We might get there eventually. Thinking models are a bit better at it. But we are not quite there yet.
You need to think about what "good taste " is to you (or find others who have already written about software architecture and take their ideas that you like). People disagree on what that even means (e.g. some people love Rails. To me a lot of it seems like the exact opposite of "good taste").
A lot of prompts about finding the right level of abstraction, DRY, etc.
An earlier example (Opus 4.5 + Gemini 3 Pro) is here: https://github.com/stared/sc2-balance-timeline
I tried as well to just use Gemini 3 Pro (maybe the model, maybe the harness) it was not nearly as good as writing, but way better at refining.
For example I am developing a game using GDscript, LLMs (including codex and claude) keep making scripts with no classnames and then loading them with @preload. Hate this, and its explicitly mentioned in my godot-development skill. What agents can't stand is a failing test. Feels a bit like enforcing rules automatically.
This is a stupid idea but it works wonders on giving taste to my LLM. I wonder if I should open source that test suite for other agentic developers.
If I have some time, the last thing I want to do with it is sharpen prompting skills. I can't imagine a worse or more boring use of my time on a computer or a skill I want less.
Every time I visit Hacker News I become more certain that I want nothing to do with either the future the enthusiasts think awaits us or the present that they think is building towards it.
The problem is that I don't know what I'll achieve manually before attempting the task.
Big bang approach could be a start, but a lot of one line guidance from specific things you dont want to see stack up real fast.
[0] https://news.ycombinator.com/item?id=47272913
The days of the deep expert, who knew the codebase inside out and had it contained in their head, are coming to an end.
In my opinion, you overestimate the ability of coding agents to, well, code and underestimate the ability of humans to really understand code.
The chart in the article we discuss appears to plateau if one excludes sample from 2024-07. So, we are not quite heading, we are plateauing, if I may.
I strongly assume the long tail is shifting and expanding now and will eventually mostly be software for one-off purposes authored by people who don't know how to code, and probably have a poor understanding of how it actually works.
Also had a similar experience in the past weeks reviewing PRs written with LLMs by other engineers in languages they don't know well, one in rust and one in bash. Both required a lot of rounds of revision and a couple of pairing sessions to get to a point where we got rid of the extraneous bits and made it read normally. I'm glad the tool gave these engineers the confidence to work in areas they wouldn't normally have felt comfortable contributing to, but man do I hate the code that it writes.
This doesn't always work as well as I'd like, but largely does enough. Conversely, doing as I go has been a waste of time.
Now some people argue that terrible code is fine nowadays, because humans won't read it anymore...
I wonder if these RL runs can extend over multiple sequential evaluations, where poor design in an early task hampers performance later on, as measured by amount of tokens required to add new functionality without breaking existing functionality.
I can’t speak for all humans, but I tend to code “nonlinearly”, jumping back and forth and typically going from high level (signatures, type definitions) to low level (fill in function bodies). I also do a lot of deletion as I decide that actually one function isn’t needed or if I find a simpler way to phrase a particular section.
Edit: in fact thinking on this more, code is _much_ closer to a tree than sequence of tokens. Not sure what to do with that, except maybe to try a tree based generator which iteratively adds child nodes.
But for the most part, it’s spending more tokens on analysis and planning than pure code output, and that’s where these problems need to be caught.
There is no thinking, no matter what marketing tells you.
It has a third year college students approach to "make it work". It can't take a step back and reevaluate a situation, or determine a new path forward, it just hammers away endlessly with whatever it's trying until it can technically be called "correct".
OH! Yeah I think this is the exact bad feeling I've gotten whenever I've tried testing these things before, except without clear and useful feedback like compiler error messages or something. I remember when I used to code/learn like that early on and...it's not fun now. I also don't think it's really solvable
They also just... Ignore shit. I have explicit rules in the repo I'm using an agent for right now, that day it is for planning and research only, that unless asked specifically it should not generate any code. It still tries to generate code 2 or 3 times a session.