As expected, Fusion was 7x slower and 4x the cost.
This isn't a knock against it, just that it I think this places Fusion into a "use it only when you need it" category.
It felt, like Fable was able to kinda grasp very deep knowledge/intelligence layers and outline solution not only in agreeable way, but rather it proposed to prioritize solution items, with discarding some of the items, which made a lot of sense to me.
While Fusion felt more like a bit diversified answer of the same class of pre-Fable SOTA models, without touching the depth of knowledge/intelligence layers, which Fable was able to get, in my very limited tests I did, while Fable was accessible.
Surpassing Frontier Performance with Fusion
https://news.ycombinator.com/item?id=48525392
And a slightly better UI here: https://openrouter.ai/fusion
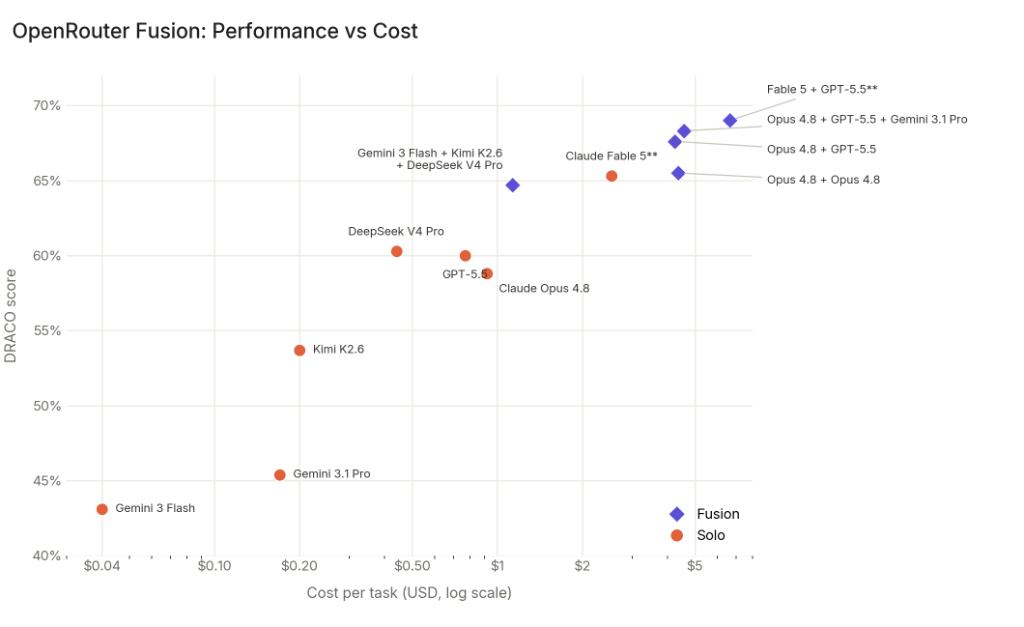
On OpenRouter's fusion API your request is routed to several models simultaneously and a judge model combines their answers into a final response. This significantly boosts performance, at the cost of time (at least on the one benchmark they tested, a deep research benchmark).
They have a Budget preset consisting of 3 cheaper models (which roughly matches Fable on that benchmark, costing half as much), and a Quality preset of 3 expensive ones (which beats Fable, but costs twice as much as Fable).
Pareto graph: https://openrouter.ai/blog/images/blog/fusion-benchmark-cost...
{kind=link}
Curiously, fusing a model with itself also boosted performance (2xOpus4.8 roughly matching Fable on the benchmark, but costing twice as much as Fable). There's a further, smaller gain from mixing different models. The main gain seems to be from additional test time compute.
Would love to see more research on this, especially focusing on the cheap models that came out recently (e.g. Fusing DSV4 with itself, or with Mimo), and to see what the tradeoffs look like between running a fusion (parallel test time compute) vs increased reasoning or turns.
I wouldn't be surprised if Fable/Mythos is a model distilled from a Panel/Council of Claude instances. Recursive self improvement is something all AI labs must be working on in some way or another.
Back in the GPT2 to GPT3 era this was a pretty common thing to do. You are effectively taking more samples from the space of likely outputs. If your model can do the task 60% of the time just take 5-10 samples and implement some kind of majority voting
It became less common to use as models got high accuracy on problems where combining results is trivial. But with a more complex judge (a competent LLM) you can still get better results by just sampling more of the output space and picking out the best aspects
Seeing this log is interesting: https://link.ekin.dev/6RzYGGX7
It came up with a decent response but I guess Opus or GPT 5.5 would do fine anyway. Gotta try it on different stuff. But this feels like it would work great on some situations.
I found that Fable didn't have as much of an impact when put in a team.
But it was/is a very pleasant model to work with 1:1. And was the first time I didn't use my primary team based workhorse in months, across 10s of sessions last week.
One scenario I can see it working is writing markdown specs before the coding starts and analysing it for gaps. That’s so few tokens that throwing as much LLM against it as possible is worthwhile regardless of cost per million tks
After extensive testing and benchmarking I discovered that when you ask one model to judge another's response you don't actually get a better answer. You are just asking it "how closely does this resemble the answer you would have given me." Additional rounds and all the "obvious" solutions that pop into your mind reading the proceeding sentence are essentially just cranking up the temperature.
I did find a solution, but it is insanely expensive. Maybe if this gains traction I'll release mine.