Which make me raise a question. Why would I install a close source black box, that will send data to a country that you can't make legally liable for even most crazy miss doings.
The market of a hosted commercial version of glm is very weird. yeah you can deploy an open source version or run it locally, sure. This.... hm, i don't know why any company would take any risks to use GLM
Not to mention, claude and gpt only exist because of massive ip theft in the first place.
Lets move to caves and if I kill you first , i'm right, if not i lost. THat's your logic.
there is ToS, and every single person who is doing distillation knows it's illegal. Also on IP theft. There were several courts, in different countries they limit certain knowledge bases and thats it. so that entire claim is baseless.
Again this is the difference. A major book publisher brought ai companies to court and won. You can't doo anything with Chinese companies even if you are book publisher of this world.
If you're already used to your TUI coding agent, you don't need the desktop agent. Although it is nice that it is there for folks who prefer the Codex App/Claude App UI approach.
For some tasks, it's better. Opus refuses tasks for me pretty regularly. GLM 5.2 has never refused a task. So for anything security-related or that touches on topics that trigger Opus's safety guardrails, I use GLM 5.2.
OTOH, for anything related to UI design, I use Opus 4.8. It's much better at taking relatively vague descriptions of user interfaces and a mockup of a related UI and combining them into an immaculate design.
For anything else, I tend to run tasks in Opus and then have GLM review them and write a Markdown file with anything it finds. Then I have Opus review the markdown file and fix the issues it agrees with. The reason I usually go with Opus 4.8 first is mainly that it's faster. Opus 4.8 is, on average, about twice as fast as GLM 5.2 running on z'ai's infrastructure for the same task. There's a large variance (sometimes GLM 5.2 is pretty fast and Opus 4.8 is pretty slow), but on average it's a very noticeable difference.
When I run into Anthropic's Quota, I switch to GLM 5.2 rather than Sonnet. I don't think there's much reason to ever use Sonnet for anything if you can use GLM 5.2 instead.
This is all pretty subjective, of course. On average, I think Opus 4.8 is still a better, more reliable, and faster model, but if it went away tomorrow and I only had GLM 5.2, I wouldn't be too sad about it; I'd get things done with GLM 5.2 just fine.
One example I've hit is working on a benchmark of how well LLMs handle Kubernetes security tasks, there's a section on them exploiting security misconfigurations. Opus 4.6 was fine with that section, 4.7 and 4.8 saw some refusals and Fable point blank refused to do any of it.
The only other model I've seen refuse is OpenAI GPT-5.5, all the open weight models seem fine with it.
Ofc if you need to do that kind of work a lot you might be able to get on OpenAI/Anthropics allow-list for cyber work.
I've also had it refuse security-related tasks, and occasionally it stops without any discernible reason.
But when there was the Hantavirus thing a while back, I asked it if there was a vaccine under development and got a refusal immediately. I’ve had a few like that. It seems they’ve implemented really poor guardrails on certain topics (CBRN and cyber) that have lots of false positives. But if you actually chat with the model itself it’s quite lucid about what is legitimately dangerous and what is just performative “AI Safety” style refusal.
But that's the only refusal I managed to get.
Edit- I see down-thread you use z.ai directly. Same concern, aren’t you worried about using it for professional stuff.
There's no customer data sent to anyone, though. I run OpenCode and Claude Code in a Docker container that only has access to a subset of my code base. There are no secrets in there, and I'm vaguely ok with z.ai using this to train their models.
That said, it's interesting that they're releasing a bunch of stuff: ZCode, OCR.z.ai, Image.z.ai, Audio.z.ai, AutoClaw and some other stuff that https://chat.z.ai/ links to. That's a lot of stuff for one org to pull off.
Figured I'd try out their Pro coding plan, seems like it doesn't necessarily give me that much quota than Opus (at least given how many tokens are needed for accomplishing a certain task), but GLM 5.2 in of itself seems like a beefier Sonnet model, pretty good.
I guess the base is whatever the profit margin needs to be this month.
[1]: https://zcode.z.ai/en#:~:text=Base%20usage%20allowance%20inc...
[2]: https://support.google.com/gemini/answer/16275805?hl=en#:~:t...
Start plan: 5 Million tokens a day (GLM-5.2 3M, GLM-5 Turbo 2M)
For individuals: (+150% quota) $18.00USD+ For individual developers with a dedicated Coding Plan quota.
The app itself is interesting to me. I can see most of the agent trace (I can't see the tool definitions and the tool input args), I can set up skills and make the agent manage them and I can define sub-agents as well.
The UI itself is a bit weird, but I guess it's not thought to be a general purpose file editor.
When looking at subscription offering by Anthropic and OpenAI, it's not even comparable, as a Codex $200 subscription can easily use a billion tokens per week on GPT 5.5 high/xhigh.
It's an interesting model from the perspective of being the most capable open weight model. But it doesn't have a solid place in this marketplace right now.
It shows potential, answer/code quality was solid, but I would need more time with it.
I'm wanting local context in the spirit of "here are 3 AI providers available, for coding tasks use this one... and for writing prose use this one... and for generating images use this one..." etc.
OpenCode was the first agent harness I used, and I have always like it. You can configure a wide variety of providers, but it's open source and has a number of core contributors.
The other opinionated option is Pi (the Pi agent harness). This is a great lightweight option and also supports a number of providers. You can also use local model servers.
i think people don't realize how much better life is over on this side, cc and codex rely entirely on vendor lock in imo.
I don't think I understand the token/cost implications of this feature
I've been using it exclusively (and extending it, see https://a.l3x.in/ai) for months with mainly GLM-4.7 then 5.1 and now 5.2 and I could hardly be any happier.
I'm still working on a "Github/Forgejo first" based workflow but also quite happy with it already, basically most of my sessions run as a ci/cd job (triggered by "/pi" comments) and generate PRs or push commits to PRs, see https://github.com/shaftoe/pi-coding-agent-action
The orchestrator knows which AI client is running in any given worktree, so it would be fairly easy to designate which AI should receive what kind of tasks.
You run either Claude or Codex in tabs for each work tree. I do have some AI TUI specific instructions, for instance codex is primitive at monitoring compared to CC. So, there are additional notes for Codex workers on how to properly monitor for new "mail."
You work with the orchestrator on the primary worktree and allow it to delegates tasks to the workers and answer their smaller questions.
It surfaces results and assisting them with context clearing when needed.
The orchestrator and workers communicate using a simple shared file system under tmp/* and together they can handle a big and varied workload.
I use iterm2, so I’ve also added iterm2 specific python that allows the orchestrator to “kick” a worker or perform tasks otherwise veto'd by the TUIs (ie /clear) by modifying the input and submitting it.
(Full disclosure: it’s my project)
It supports MCP (unlike Pi), sandboxing (with user-mode networking), and runs efficiently at huge contexts.
https://codeberg.org/mlow/lmcli
(The screenshot in the folder is a little bit out of date, but is still representative of the overall look)
I prefer having a GUI for diffs and session history,but if you prefer TUI you can just use OoenCode
China have a history of stealing IPs/trade secrets and Chinese court favored its own local companies. while US have a robust court that can enforce IPs. if you want to risk your company's IPs/trade secrets/data for some cheap token. Go ahead and use Z.ai's services.
It is essentially a black box with full user permissions, meaning you are just handing over your entire system to a Chinese-owned server. With OpenCode and its GLM provider, at least I can monitor which files were read, which were edited, and what commands were executed.
Not to mention that Chinese national security laws legally obligate companies to cooperate with state intelligence and counter-espionage efforts [0]. If you have this installed on a corporate workstation, and your company is large enough, the possibility of them spying on you is not just a risk—it's almost a certainty.
[0]: https://en.wikipedia.org/wiki/National_Intelligence_Law_of_t...
I also consider Microsoft to be the biggest industrial spy in the world, them and google both are no doubt mining everything you type into office / gsuite, all your emails, etc. But nobody bats an eye when you write a word doc about some sensitive matter.
If my customers thought I was feeding their data into a Chinese owned LLM API (which to be clear I’m not), I don’t think it would go over well, and I’d be exposed legally to all sorts of things.
So the reason is risk aversion and desire to participate in US / western commerce. One can debate the actual threat, but why would you ever risk sending your data to a processor perceived as dodgy?
Suppose a US citizen, residing and working in the US and never traveling to China, crosses The Powers That Be. Which Power is more likely to do worse things to said citizen? Pretty unlikely they'll be rendered to one of the illegal Chinese jails in Brooklyn, more likely they'll be sent to Gitmo or a black site.
That's why, all other things equal, I try to keep my own government happy or ignorant, but don't really mind what I share with foreign governments, especially ones who won't forward the info to my own government.
This is worse don't get me wrong. But doesn't take away anything from the fact that the case here is indeed abysmal.
Surprises me that on Hacker News of all places, where people are tech-literate and educated, people still seem to trust our companies and governments as if they didn't have an established track record of spying and screwing us over.
You know you're sitting here on the open Internet complaining about the US government with literally zero fear of any repercussions in any sense whatsoever?
You should go to an actual authoritarian country and just ask someone their opinion on their government.
The difference between flippant, hyperbolic complaining (you) and someone who will actually glance over their shoulder and totally clam up in response to that type of question is quite chilling in reality.
The fact that China acts punitively with the data they gather on their citizens, and the US does not (yet), doesn't change at all the fact that the US actively harvests that data in a very aggressive way.
There may or may never be a time where the US starts acting on it, covertly or openly. But still, they're siphoning all of my data, and all of yours too and I don't see why we are downplaying it by saying it's worse elsewhere.
A country that siphons up data and then arrests you for saying mean things about Dear Leader is a lot, a lot worse than a country that siphons up data and then basically can't do anything with it.
I don't think it should be downplayed, but it certainly isn't the same. It just isn't. It's ridiculous and counterproductive to describe it as such.
There are very few exceptions, and of those that exist virtually all are under existential threat constantly.
Nevertheless, Americans thinking they are morally superior to China is always quite funny.
This administration is corrupt, cruel and doesn’t care about human rights.
And the worst is… Americans have voted for that administration…. twice!
I digress…
This has never happened in China, and will never happen, nor anything like it. Some open oversight is almost always better than possible secret oversight (and do you think that the Chinese government has user privacy on even its top 10 priorities?)
But yes, US intelligence has killed and ruined the lives of far more people than China has. Not sure how so many people buy into the narrative that they're protecting freedom and democracy.. They're protecting their freedom to kill and crush all their enemies and control every "democracy" on earth.
Reminds me a bit of the old “is your adversary Mossad or not Mossad” decision matrix https://www.usenix.org/system/files/1401_08-12_mickens.pdf
I'm no apologist for the US Intelligence and related organizations (not by a very long shot), but that is a very extreme statement to make.
Or are those not people to you?
China doesn't go around the world using it's military to force it's will upon people.
Every decision the US military, or State Department makes is a product of US intelligence
The foundation of US Intelligence was built by people who literally cried in the meeting when FDR broke ties with Nazi Germany. They proceeded to pardon and protect the perpetrators of genocide after ww2, then went onto hire them. US intelligence is literally built by Nazis.
The CCP was founded on the back of a peasent uprusing. The US is the 4th Reich and the most evil government to ever exist. The people of the US are generally good people, but the Empire itself is pure evil that fuels itself with death and destruction.
No, they use it on their own people. Come on, the USA is bad, but comparing it to China isn’t going to show the contrast you are looking for.
PLA has always been focused on battling other Chinese, it’s literally in its name [the L stands for liberation, it’s still an army aimed at domestic subjugation rather than doing anything abroad).
By the way, some pedant recently asked why anyone would run software with only a few stars. My thoughts on that are minimal: people can practice whatever slop logic they want. I've architected and built systems that handled tens of thousands of users. I'm not fucking around. The way I build isn't typical, and I don't suggest anyone try to mimic my approach, but it works for me and the way my mind processes complex systems.
To the peanut gallery: use it or don't, but don't give me a hard time unless you're ready to get one back. I've made plenty of mistakes in my career, and accountability is a crucial part of growth. I'm more than willing to work with anyone using my code, provided they bring valid, substantial criticism to the table.
The US is certainly inching in that direction but it’s not like someone from the US government sits at Anthropic’s HQ reading chats from state people of interest.
1) there is a very non-zero chance that the US government also has that data from OpenAI and possibly Anthropic
2) unless you are asking the chinese models to draw up plans to overthrow the chinese government, it's extremely unlikely they would ever care.
while china has a track record of harassing it's own dissident citizens abroad, if you're not chinese and not trying to subvert their government (or are a high-ranking government official yourself), it's kind of silly to suppose they would ever care about you or what you do.
and if you have information they want for their own national development purposes, like EUV engineers, they are much more likely to offer you fabulous amounts of money instead of try to intimidate or threaten it out of you.
even companies that proclaim zero data retention have yet to produce a mechanism that makes me trust that claim
PRISM ... XKeyscore ...
> The US is certainly inching in that direction
Itching to go in a direction that (publicly known) they have been in for decades now.
Do you really think the US government doesn't get access or couldn't get access to any of your chats with Claude?
Actually there are more such cases against the USA than China in public.
You mean, like Windows and Android?
For GLM Coding Plan subscribers, quota consumed via Coding Plan for GLM-5.2 in ZCode is discounted by the coefficients below — the same usage draws down less quota, roughly 1.5x the effective allowance.
Peak hours (14:00–18:00 daily) 3x -> 2x
Off-peak (remaining 20 hours) 1x -> 0.67x
> Explanation and Recommendations Regarding Usage for Plan-Supported Models
> Note: Peak hours are from 14:00 to 18:00 daily (UTC+8).
Here's the message: "Cannot connect to API: write EPIPE"
(If this comment is too formal, I'm sorry. I used Google Translate to it [this line was NOT translated])
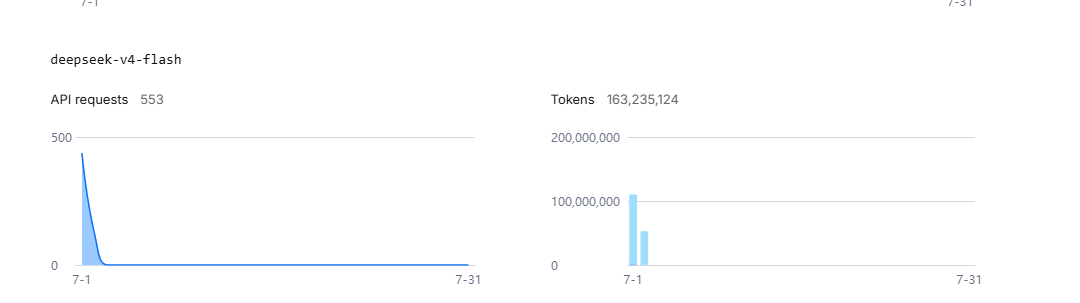
At 200k context that is only 85 requests for a whole week.
{kind=link}
But mostly vendor lock-in, I imagine.
And most of the advancement and experimentation happens in some random 0-star github repos.
pi-tmux is one such example (seems to be archived now) which inspired me to use tmux as communication layer and provide visibility of subagents of multiple models in their native harnesses [1].
There's also herdr, which is not 0-stars, but is super interesting but lesser known project [2]. This also has interesting substrates to allow agent coordination.
None of these are harnesses per se, but they're pointing towards clear gaps in existing harnesses. For example, we've known for a while now that compounding knowledge of different class of models achieves better performance. Why is there no harness where this is a native functionality? And there's no harness where subagents are first class citizens both in terms of capabilities and UX.
Do they really correspond roughly? Seems like they’re trying to suggest a discount while still being worth a significant amount of monthly spend.
I've written up an explanation of what trips small models ups and how the harness can address that here https://yogthos.net/posts/2026-06-08-dirge-code.html
I suspect smaller models need more work than is practical to fit harnesses around. The smaller the model, the more work, and it doesn't carry over to other small models.
Deepseek r1 7b could not emit tool calls to save its life, gemma4 e4b couldn't get the names of files right, qwen3.5 4b gets stuck in dumb rabbit holes, I pointed it at a ruby script and asked it to run it, it tried running it with bash then got caught in a loop investigating.
Noble effort though! I guess I'll keep working on my barebones ruby_llm harness, with very tempered expectations. Each of these failure modes can be worked around, but there's too many of them to work around in the general sense.
I find I tend to view agentic coding similarly to a genetic algorithm. The model is the mutator function, and the harness along with the tests acts as the selection function. Each round the model generates some plausible code, it gets tested against the constraints, the model gets feedback and iterates on it until it converges on something that's workable. So, the real trick is to make sure the environment is producing correct pressures to guide the model in the needed direction.
Another interesting project in this space I can recommend checking out is ATLAS https://github.com/itigges22/ATLAS
For example, so far I haven't seen any evidence that LSP integration improves performance for small models vs using grep via a bash tool.
As it stands, it's kind of subjective, you just have to try the harness and see if the model seems to be have better than with the other ones you've been using.
Even without having hard numbers, it's pretty easy to see from the log whether the model is getting stuck or not.
It does have a 1.5x usage promotion for GLM 5.2 on the coding plan so now is a good time to test it...
- https://igorwarzocha.github.io/howcode/
- https://github.com/ruuxi/stella
Not using Pi, but based on PI (no extensions possible)
But it already works really well with existing harnesses, I'm not sure why a dedicated one is needed?
I use it with https://swival.dev and everything works perfectly, no tool calling issues and it works fine with long sessions.
You can do a brainstorming with web on a remote container prototyping based on that brainstorm on another container with no network access.
The one thing that is less trustworthy is using local agents for service management, you definitely want to have them scoped to dev/testing. I would never trust an agent to execute any command in production or sensitive data at all
I have read about people giving an agent full access to their main system saying they have nothing of value. To me, that's a strange opinion to have with the distinction between what's private and what's secret.
I've also started creating new github deploy keys for each repo in use on a VM, so the blast area for any given agent disaster is "a couple/few github repos and whatever credentials were needed for the agent/model".
I wouldn't let a coworker, even one I know pretty well, log into my personal account on my machines...why would I let an agent that can be tricked into uploading all my credentials to an attackers web server?
The agents have sandboxes, but those are loose. Not enforced by anything outside of the agent harness itself.
You might want to check out Ant's open source srt [0], I use it to contain my local coding agents. It's strict by default and enforced at the OS layer.
[0] https://github.com/anthropic-experimental/sandbox-runtime
I do the same: my agents run in a hardened VM on a hardened Linux machines in a separated network in my basement. The magic of ssh makes this setup transparent for me on my desktop. But extremely hard for my agent to do nasty things.
This way, all members of the student union were able to install any software they wanted to on the student union computers without having to give out blanket root access to the members. Only a select few members had full root access.
There’s other ways to achieve the same too.
And you can do this exact same sort of thing for the user that your agent runs as too, without having to give it access to do everything that root can.
After you had been a member for a while and demonstrated that you mostly knew what you were doing, they’d give you full root access if you had some reason to want it that they agreed with.
And thanks to the dedicated suid program that exec’d into apt, wanting to install additional software was not a reason to be granted full root privileges since everyone could already install packages from the apt repositories this way without full root privileges.
Along with full root access came basically just a couple of simple rules, one of which was:
Do not abuse your root access to walk into other members home directories.
That rule was put in place after a previous member with root access had used the root privileges to copy the homework of another member into his own home directory without asking the other member for permission to see his work.
Aside from that one thing happening that one time, there hadn’t really been anyone doing anything malicious AFAIK. We were a rather small group of members in this student union, and it was a pretty chill and nice place. People came there to hang out, drink beer and tinker with electronics and computers.
There wasn’t much that root privileges could be abused for anyway. Regular members could already use all of the machines via graphical login at the desks, and remotely over ssh. Really the main two things anyone could have done maliciously would be to steal other people’s homework (like that one guy was kicked out for doing), or to steal credentials from others (no known cases of that happening there).
And if someone had started acting really maliciously, using the student union computers to attack the wider network, the university would have been on top of that real fast. The computer network of the student union was a subnet of the university network, and this university had a very competent crew of people watching over the university computer network as a whole.
A friend of mine once wondered how many computers were on the university computer network in total and did a port scan from one of the university computers (not from the student union computers). It did not take long from he started the port scan until university employees contacted him and gave him a stern talking to, and also told him the proper way find the answer to how many computers were on the university network.
And, we're not talking about hypothetical attacks here. Prompt injection attacks have happened. Supply chain attacks that agents fell for have happened.
https://venturebeat.com/security/six-exploits-broke-ai-codin...
I'm going to "security in depth" these gullible little thinky guys in my computer, but you do what makes you happy.
You can't see how the agent having no access to anything other than what it's working on is safer than the agent having access to my home directory with all of my credentials?
Look, you do whatever you want to do with your agents and your computer. I'm going to...contain them.
https://venturebeat.com/security/six-exploits-broke-ai-codin...
In that case, maybe you want VMs at hosting providers. There are companies building ephemeral VM and container orchestration layers for this kind of thing, I haven't played with them, though. It seems like a reasonable idea, though. One isolated environment per project or repo. Only the secrets needed for that one project and an agent that can't reach outside of it.
I've considered building something along those lines, and actually do run my security auditing benchmarks in containers automatically (that was originally to prevent the models from cheating, because you can disable network, but it has other pleasant side effects).
It's actually not that big of a lift these days to spin up containers on-demand and put just what's needed inside it (including the authentication info for the agent). I probably should automate it..right now I just have four permanent VMs setup for my various types of work: My day job, my open source projects, my benchmark and security work, and some side projects. Plus some temporary ones for experiments.
I've never used IDEs and never will, why are these things being constantly shoved down our throats?
I also maintain https://github.com/nothingnesses/agent-images which allows you to use Nix to reproducibly spin up OCI container images containing agents and any other tools you need for development and use these with agent-box.
I use both at the moment to work on some personal projects with agents, where I set up multiple separate git worktrees for the agents to work in, preventing them from accessing anything outside of the worktrees and from trampling over each other's work.
What's your setup like and what do you use it for?
I have a M2 Max MBP with plenty of ram and I use VSCode + Zoo Code plugin with Qwen3-Coder-Next-GGUF:UD-Q4_K_XL to run local agentic coding sessions, but I'm intrigued by being able to run headless as I could probably run multiple instances in parallel to do stuff?
Like are you using UTM with some pre-built VM and a local LLM?
Curious.
shameless self-plug. I've been dogfooding it for the last 3 weeks now.
Edit: my theory is they wanted to mimic being the primary provider in a quick way with a lot of string replace. Though they could have added opencode back as a regular provider.
By the way, their repo was a bit weird with no changelogs at all. It seems to be picking up speed now with their communication. I actually read in the changelog just now that their Compose (plan/executre/review etc. something like that) flow is now deterministic with software instead of just prompts. That could be really good.
Harnesses are quickly becoming critical components of the "model" itself imo. Not shocking to me at all that a company that spots a revenue opportunity is keeping its harness closed source.
A harness is that covering every blind spot or sub-optimal but probable output people have hit in the wild, and a lot of problems just have better solutions if you say "break problem A into subproblem B and subproblem C, then solve".
Here on HN we discuss facts, jumping straight into racism has no place here.
That idea is wrong, though. These same people thinking harnesses are part of a moat are also boasting that s/ware is easily writable now.
There's no secret sauce in a harness that you can't vibe-code into your own harness.
I'm not saying you're wrong necessarily, but I do think that when the actions and words of a company conflict, it's a pretty safe bet that the words are just posturing and the actions better reflect their actual belief. In this case, regardless of what they're saying about software being easily writable now, they clearly seem to at least think there's something valuable in the harness if they're not open sourcing it.
Except you'd need the knowledge of what to vibe-code, no?
What knowledge? If you've used a harness, you know what it is supposed to do for you!
What further knowledge do you need that can't be extracted from an existing harness?
It is essentially a black box with full user permissions, meaning you are just handing over your entire system to a Chinese-owned server. With OpenCode and its GLM provider, at least I can monitor which files were read, which were edited, and what commands were executed.
Not to mention that Chinese national security laws legally obligate companies to cooperate with state intelligence and counter-espionage efforts [0]. If you have this installed on a corporate workstation, and your company is large enough, the possibility of them spying on you is not just a risk—it's almost a certainty.
[0]: https://en.wikipedia.org/wiki/National_Intelligence_Law_of_t...
no. they. are. not.
Some people are just terrible at it.
Also you don't need to believe me. There is enough evidence in the open source space.